

What we can learn to better manage a high volume of requests.
The pothole season is greatly underway. Because of their high number, Canadian cities and regions have no other choice but to prioritize such requests.
Small, medium or big holes, the asphalt must be repaired sooner rather than later. With the goal of repairing them as quickly as possible, the priority is to ensure the safety of citizens. The satisfaction of these same citizens is put to the test and that is where the main challenge lies; meet everyone's expectations in a timely manner.
This situation is like many customer service departments that sometimes face waves of internal requests from their customers. Moreover the HDI report mentioned that 61% of the companies with a support center saw their number of requests increase in 2018.
Manage a large volume of requests like a pro
So how to manage, with the same number of resources, a high volume of requests? How to overcome the workload and meet the expectations? Or what happens if a major incident slip's through the "lower priority" requests?
Beyond the addition of staff and expertise specific to your problem, here are some ways to solve this kind of situation.
Master the Volume
There are many ways and methods to handle a high number of requests. Depending on the operations, the type of ticketing processes and tools in place, service center managers need access to legitimate concrete solutions.
Assignation
First, assigning tickets to appropriate teams or resources is essential. Unfortunately, there is no superhero or opportunity to clone your best assets to process this rush of tickets. Assignment is therefore a must, but in which order and according to which procedures?
Manual assignment to a queue, group or specialized resource is a valid option. A "round robin" method is also a solution often used by default.
In the event of momentary congestion, the implementation of automated assignment rules nevertheless speeds up the processing of requests.
Another method relies on the owner of a CI or configuration item that is part of a CMDB (Configuration Management Database). Following our example, if a breakage of equipment causes several impacts in the delivery of services, the owner of the CI is responsible for and assigned to each of the requests related to the said equipment.
Finally, self-assignment also allows for quick ticket support.
Prioritization
It's all about prioritizing the major requests instead of incidents of less importance or the one that causes the least impact.
Response and resolution times are key indicators of your customer expectations. This data is both useful for internal improvement purposes and for justifying actions to requesters who require compliance with these agreements.
Based on the level of impact and urgency, a priority matrix makes it possible to establish priority levels easily linked to a request.
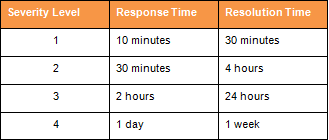
Major Incident
Let's go back to our context.
The other reality is that these larger or smaller municipalities are coping with large volumes of incidents within a short period of time. If a portion of the roadway or other landslide occurs, the small holes are relegated to a lower priority.
One of the solutions: A a major incident solution would be to constitute a team dedicated to these major incidents.
Transform Key Metrics in Key Indicators
Some metrics also allow you to identify potential improvements :
- Response time
- Resolution time
- Incident processing time
- Number of late resolution requests
- Number of first level calls
- First level resolution ratio
By following the ITIL® framework and for these metrics to be representative of your operations, it is beneficial to distinguish between an incident (example: server failure) and a service request (example: request for arrival of 'an employee).
For employees working at the service desk, an incident represents an unplanned task that interrupts the job, while service requests are operations that can be scheduled.
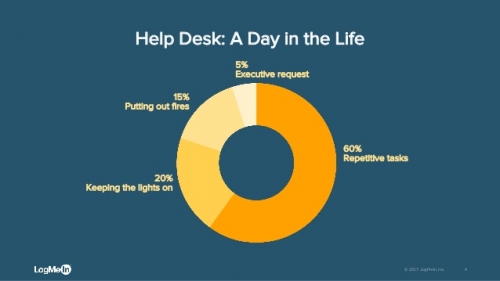
Thus, measuring the percentage of work on these incidents - or when something is broken - is a good indicator of this extinguishing fires mode or known as KTLO (Keep the lights on).
According to a LogMeIn survey, this state represent 20% of most helpdesks ;
Closing incidents related to a parent problem
When a situation brings a large flow of incidents, keep in mind that these tickets, if not closed, will pollute your database and your metrics.
After you identify and resolve the problem, be sure to close the incidents by linking them to the parent problem.
Audit Your Ticket History
Among your past results, some requests are recurring and require minor actions, while others are related to high value activities. This ticket audit may reveal that certain requests for services or incidents must be treated differently.
From password reset to integration issues, every employee faces technology and work-related issues for which they need help. To reduce the number of simple and repeatable incidents and service requests handled manually by the IT Service Center by prioritizing the types of issues and ranking the most common.
Your IT team can allocate the right resources to improve problem resolution time. With this you can identify:
- Which problems require a more standard process?
- What kind of knowledge users need to access?
- Who will fill the gaps through the knowledge base?
Your Knowledge, Your Team's Capacity
Building a knowledge base adapted to users can counter this high volume.
A knowledge base can include many items such as FAQs, videos, forums, procedural sections, access to company-specific terminology, and so on. To create a more employee-centered knowledge experience and ensure that your key employees' requests are answered, ask the following questions:
- What kind of format do they prefer?
- How do you measure the effectiveness of the knowledge base? How often?
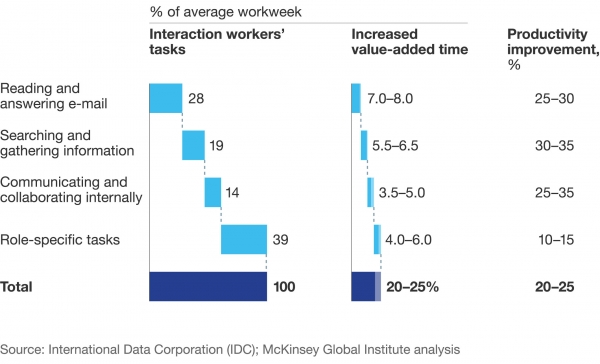
A recent study by McKinsey rightly pointed to an increase in productivity when knowledge is shared. In the example of a sudden increase in the number of queries to be prioritized, being on the same page can make all the difference for your customer's satisfaction.
Publish Knowledge for an Optimal Employee Experience
Want to reduce the number of tickets submitted to your support team during such emergencies? Your colleagues prefer self service? Enjoy a portal, a perfect channel to receive categorized and prioritized requests according to your parameters.
Remember that the initial creation of knowledge is not fixed. Once the knowledge is published, use key metrics, user feedback, and reviews to improve content and better meet the needs of your employees.
Being able to provide employees with an easy navigation solution will encourage user engagement. The employee-centered approach includes:
- Simple and easy to navigate knowledge provisions, reactive on all devices
- Intuitive knowledge flow automatically adapting to your employee's career path
- Guided stages, videos and demonstrations divided into small sections for easy learning
- Featured links for major quick access requests
Be sure to test your new knowledge base and self-service tools for a seamless employee experience.
Useful Automation
Implementing automation, especially at the level of recurring requests, is important for the effectiveness of any team in case of numerous calls. Using business rules or workflow, task management will be simplified; all will know his tasks and the moment of accomplishing them.
Here are some additional readings on process automation:
- Managing better business processes
- Useful IT Service Management business rules and workflows
Building a human and accessible service center
Finally, if a major break causes a large flow of requests to your service desk, consider other internal communication channels that can convey the information or direct your users to the right information.
Alerts linked to "knowledge articles" or the promotion of your self-service portal can increase the number of pre-categorized tickets and, by the same token, allow your teams to respond to the large volume of requests.
Considering this article, do you have any ideas on how to put more humane service management in place to deal with unforeseen scenarios?


